









Computer Vision gives machines the sense of sight. Thanks to advances in artificial intelligence, Computer Vision has evolved at a break-neck speed in recent years. The technology that has made autonomous vehicles possible is also being widely used by fraudsters to automatically index and classify images and defeat web security systems that include a visual challenge, requiring user interaction.
Manipulate Attackers’ ML Models
To defend against advanced machine learning-driven attacks on Arkose Labs’ enforcement challenges, we have introduced a new image generation technique, called Adversarial Image Generation. We use this technique to defend against some of the latest computer-vision models that attackers use. Using effective perturbations, this technique successfully defeats the attackers' machine-learning models, while keeping the required pixel changes to a minimum.
At Arkose Labs, we witness myriad attacks. To defend against such a large variety of attacks, we generate several sets of images for each puzzle. Each image set has unique settings, such as different backgrounds, styles, or instructions. These different settings help fool the attackers with different distribution of pixels in images and different outcomes.
That said, machine-learning algorithms are good at predicting data they have never seen before. As a result, the current image-generation method may not always work as expected. Therefore, we developed a new image-generation method, which adds adversarial perturbation onto the images to manipulate attackers' image recognition. Recent research has demonstrated that it is easy to fool deep-learning models with certain noise on the images.
.
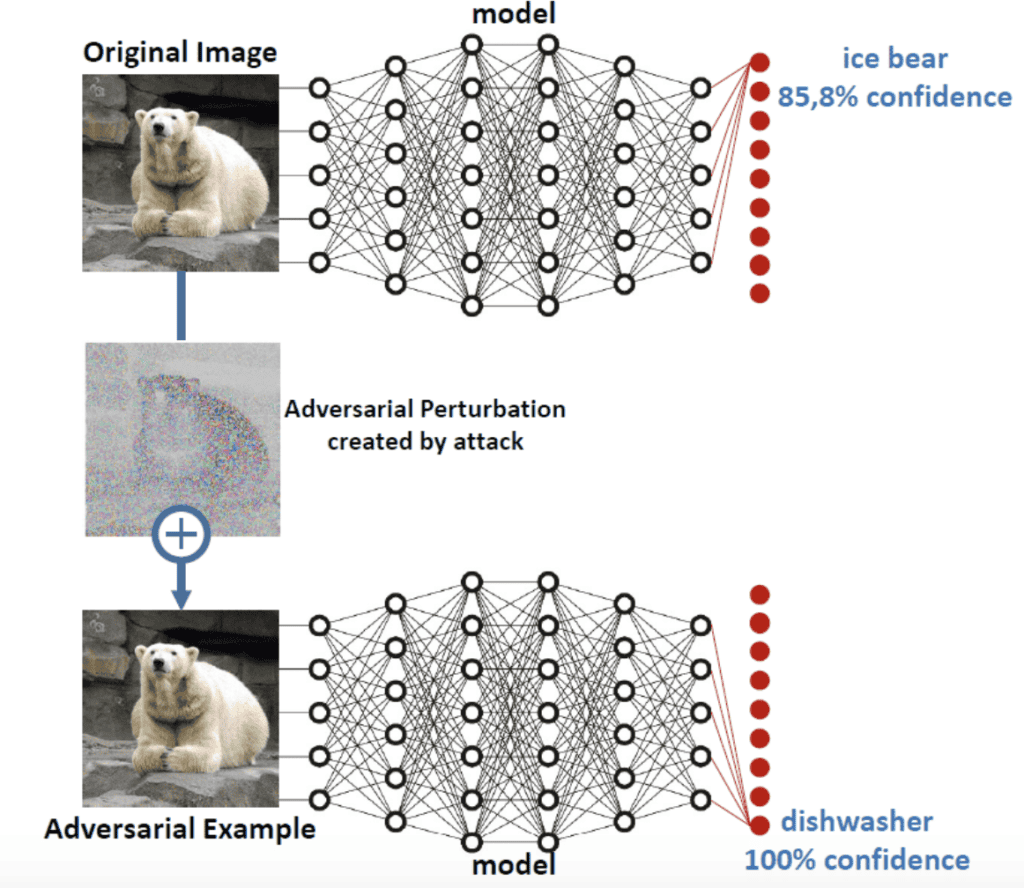
Fig.1. Adversarial Perturbation (Ref: https://arxiv.org/pdf/1906.00204.pdf)
Originally, the model can identify the image correctly. Adding adversarial noise onto the images completely fools the model. The machine-learning model could correctly identify the original image as a picture of a polar bear, but got fooled into seeing it as a dishwasher after the noise was added.
To calculate adversarial perturbation, we can use a fast gradient-based method and optimization-based method with an ensemble approach. Various studies on this domain show that it is possible to transfer the perturbation, generated from the ensemble approach, between different computer-vision models. This method is used for adversarial images to defend against different machine-learning attacks.
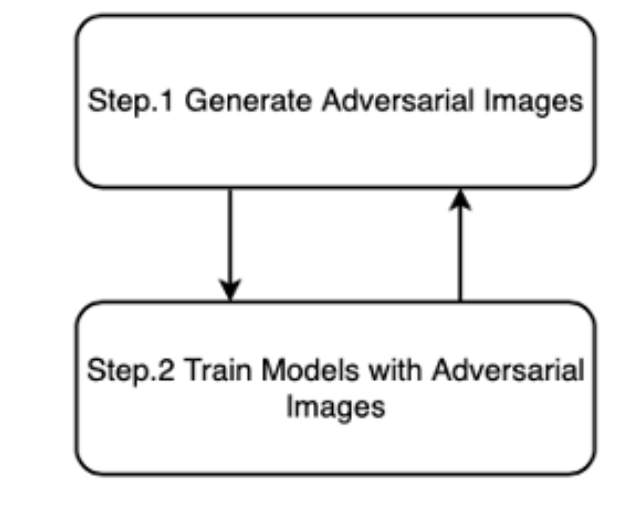
Fig.2. Adversarial Perturbation Workflow
The adversarial image generation is conducted as a cycle. First step is to generate the adversarial images. Second step is to train the trained models with adversarial images. Since the attackers can train on adversarial images, the flow will keep generating adversarial images with the models trained specifically on adversarial images before. This way flow can set the noise higher and harder at each iteration.
The ‘Hand Puzzle’ Case Study
To demonstrate the defensive and training strengths of an adversarial image, let’s consider a case study, described below. This case study is a hand puzzle, as shown in Fig.3. The correct images are the ones with a total of four fingers, the rest are incorrect.

Adversarial perturbation method helps create one of the correct images, as shown in Fig.4 below. A human may not notice the difference between the two pictures, apart from some light discoloration on the bottom right hand in the second image. The machine learning model, however, will not be able to recognize the image and classify it as incorrect.
Fig.3. Data Visualization of Hand Puzzle

The first image in Fig 4 above is the original image (correct). Second image is the adversarial image (incorrect). Third image shows the difference between the original and adversarial image. The last image is the magnified difference of the third image.
Defensive Strength
We test the images with the most advanced machine learning models. We train these models internally with good accuracy. The results are as shown in Fig.5. The game accuracy for the adversarial bucket decreased to around 3% compared to 8% for the old images set.
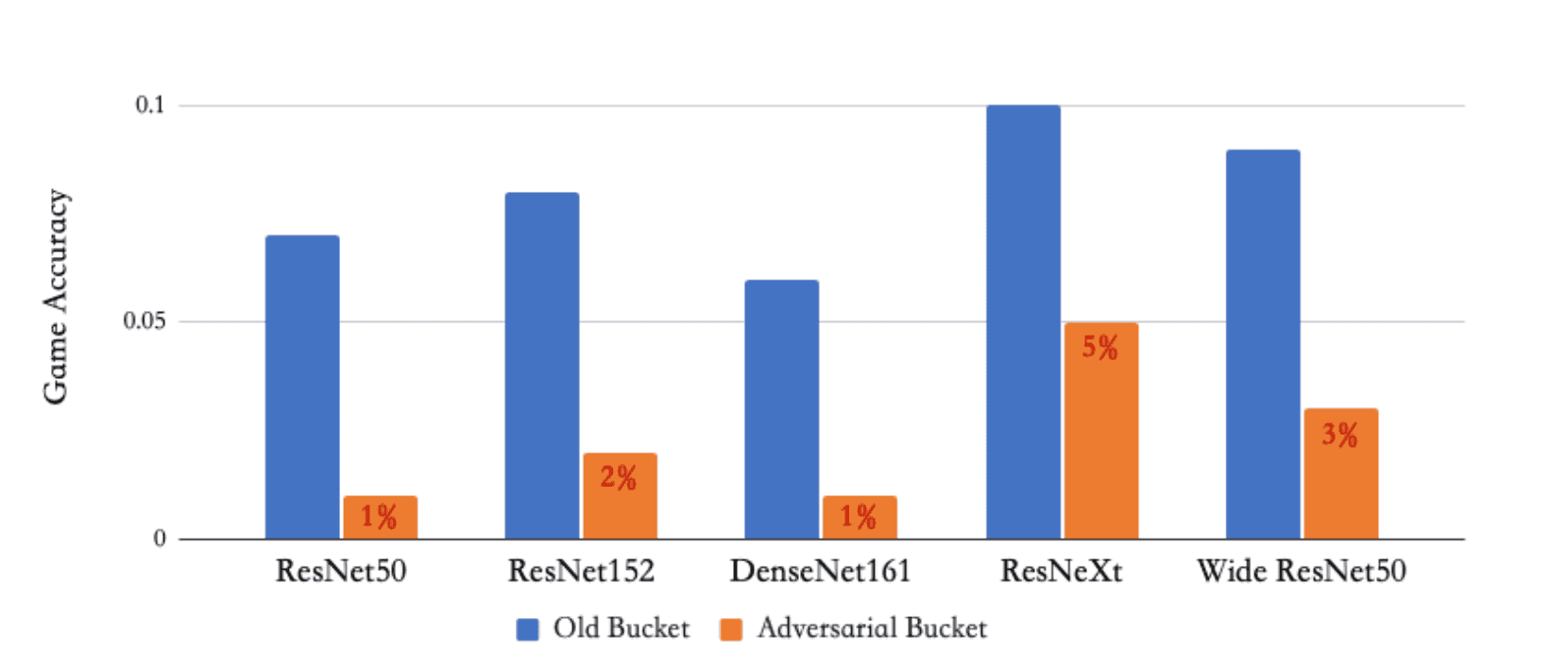
Fig.5. Game Accuracy of Old and Adversarial Bucket against Machine Learning Attack
Training Strength
Given their tech prowess, attackers are still able to collect adversarial images and train machine learning models on these images. A minor pixel change in the adversarial buckets, may make the training easier for attackers, which may be a cause of concern. Fig.6 shows that even with minor pixel change, the models still need to relearn the adversarial images.
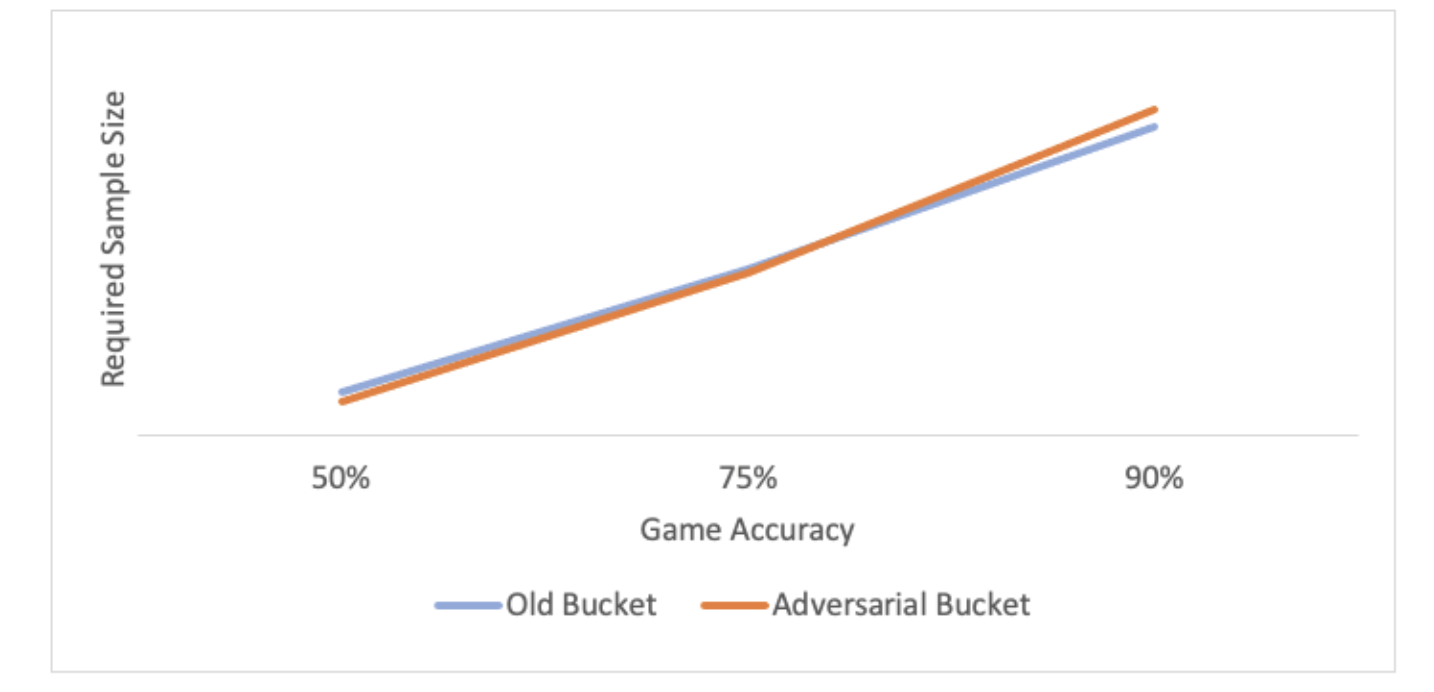
Fig.6. Sample Size Curve of New and Adversarial Bucket for Machine Learning Training
In a situation where attackers can train on adversarial images, the flow can keep adding noise on top of the adversarial images with the same defensive and training strengths, as described above.
Defeat Automated CAPTCHAs with Adversarial Perturbation
Here at Arkose Labs, we are constantly innovating to empower our customers to stay ahead of evolving attack tactics. Using adversarial perturbation, we help them defeat automated CAPTCHA solvers and protect their business and consumers from automated bot attacks. To learn how we do this, please book a demo now.

6 Pillars of Future-Proof Attack Detection
Share The Blog
