














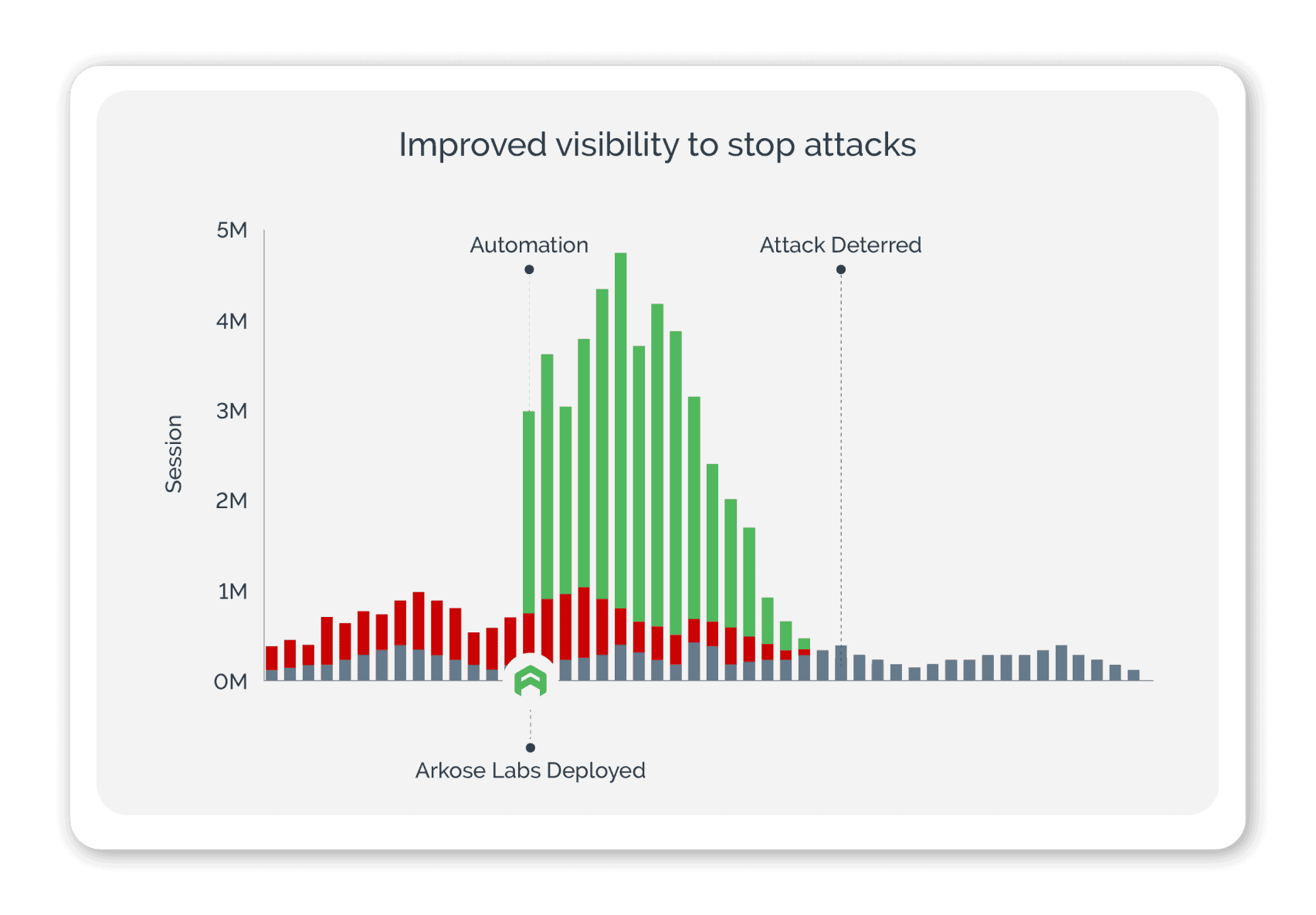

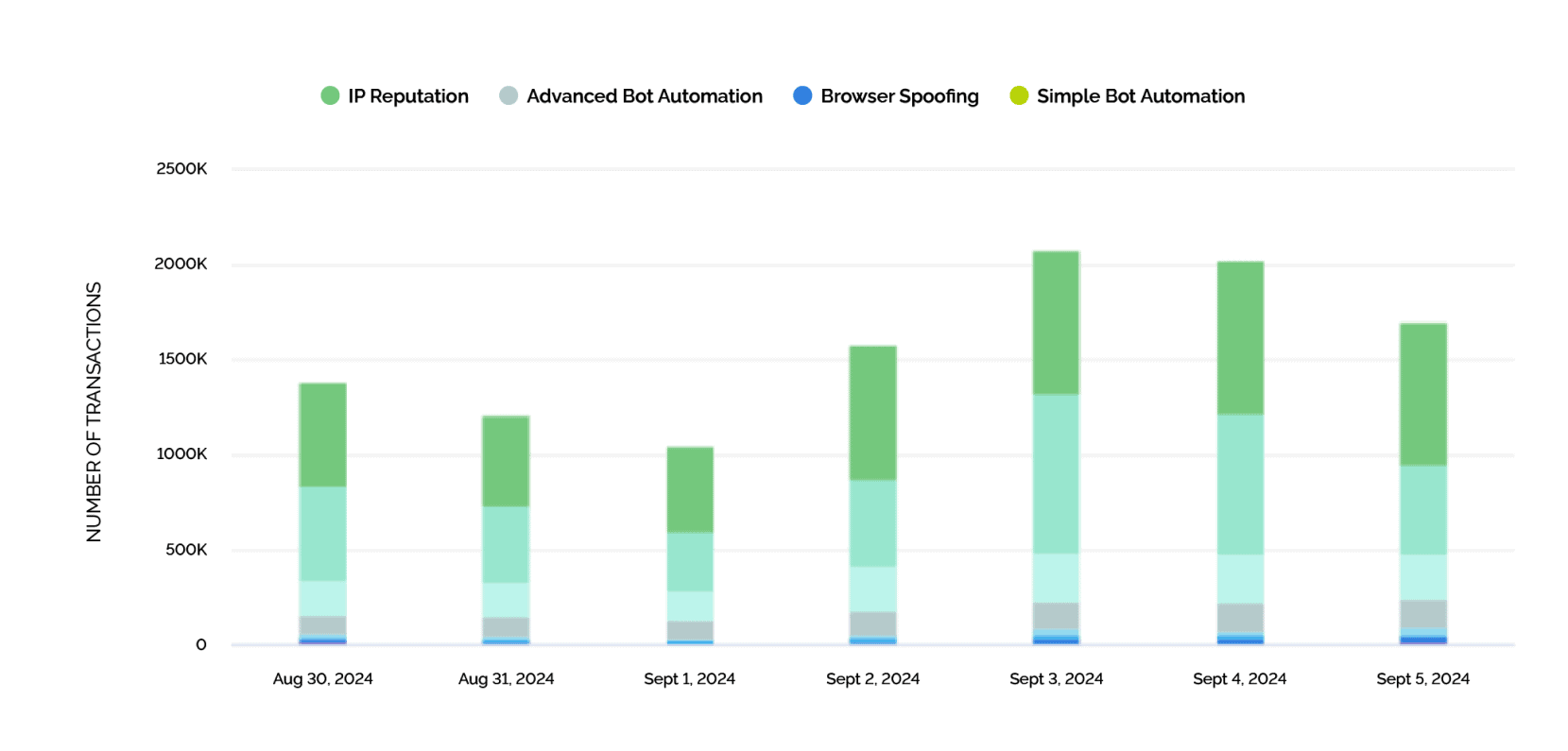









ACTIR: PROACTIVE DEFENSE
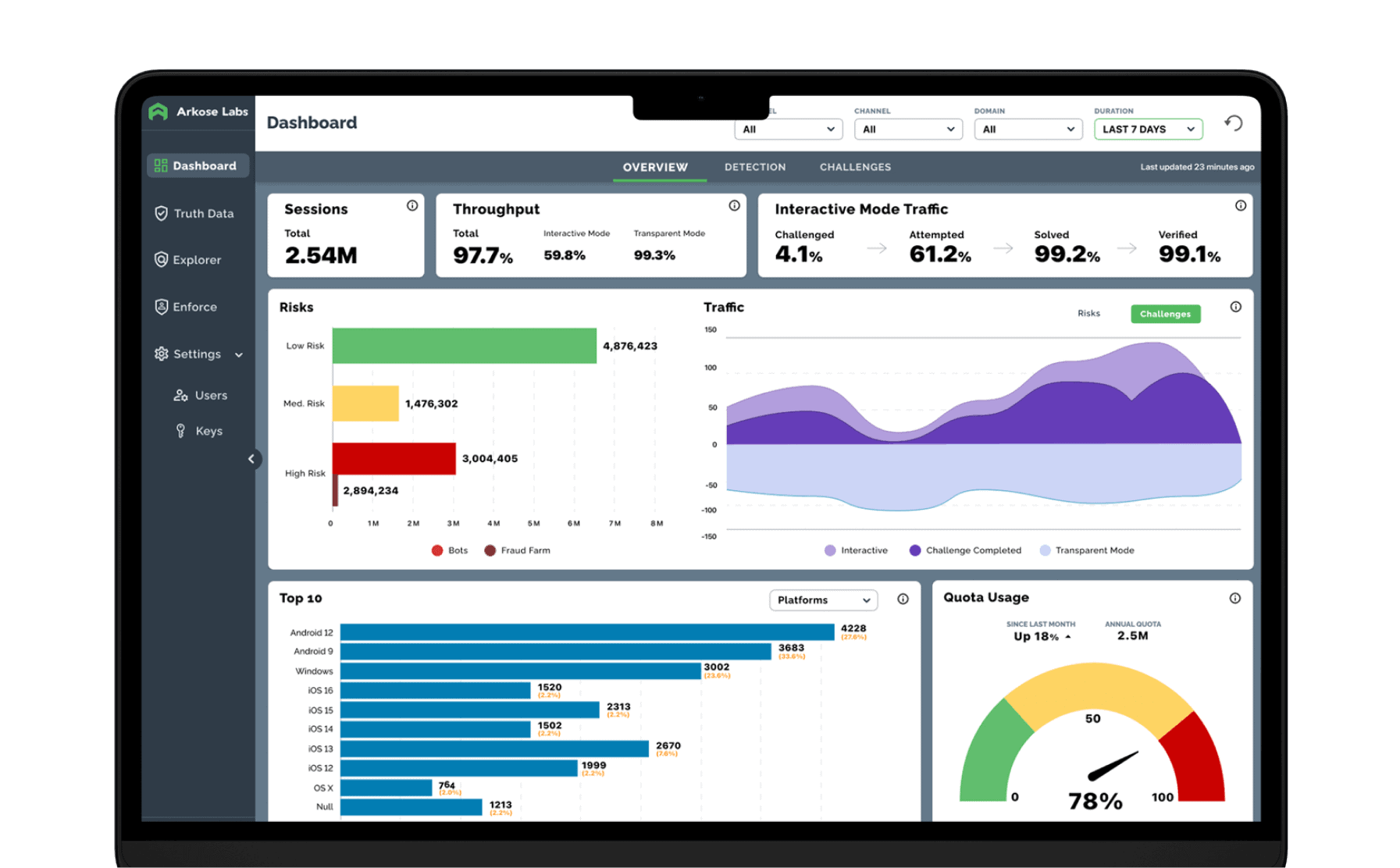
The Arkose Cyber Threat Intelligence Research (ACTIR) unit conducts proactive threat hunting, risk intelligence gathering and other counterintelligence methods to provide vital, fresh intelligence.
SOC teams continuously monitor for new threats and collaborate with ACTIR. This feedback loop ensures seamless collaboration between the SOC and ACTIR, enhancing the overall accuracy, timeliness, and effectiveness of your cybersecurity defense.






